
Redis数据结构详解(4)-为了节约内存的数据结构(压缩列表ziplist)
前提知识 🧀
前面几个文章里我们介绍到了字典 dict 和跳表 skiplist,它们都是 redis 为了追求性能而开发的基本数据结构,里面或多或少都借助了一些辅助的元素;例如字典 dict 在 rehash 时会同时存在两个哈希表,又或者跳表 skiplist 里节点多了层的结构,这些设计都是为了追求性能而牺牲了内存空间。
如果你多多少少了解 HashMap 的底层原理的话,你就知道:
在JDK1.8中,随着元素越来越多,HashMap发生hash冲突,桶中元素大于等于8个,并且容量大于等于64时,会由链表形式转化为红黑树结构;而当桶中元素降到6时又会转换回链表。
为什么有这样的变化呢?因为这体现了时间和空间平衡的思想,元素刚开始并不多时,链表的空间占用是比较少的,并且由于链表短,查询需要的时间也没有太大问题;可是随着链表越来越长,查询的需要的时间也就越来越长,就需要用占用空间大但是查询更高效的红黑树来帮忙了。
时间 or 空间,看来所有的数据结构都离不开这个命题。
而我们今天要说的压缩列表 ziplist 就是 redis 为了节约内存而设计开发的数据结构,并且作为列表键和哈希键的底层实现之一。
压缩列表 ziplist 的“登场时机”
- hash(下面条件满足其一,hash 会由压缩列表 ziplist 结构转成字典 dict 结构)
- 键值对数目超过 512。
- 插入一个 value 长度超过 64 的键值对。
- sorted set(下面条件满足其一,sorted set 会由压缩列表 ziplist 结构转成 zset 结构——包含一个 dict 和一个 skiplist)
- 键值对数目超过 128。
- 插入一个 value 长度超过 64 的键值对。
PS:在 ziplist 转成其他数据结构后,不会再退为 ziplist 结构。
压缩列表的结构

各个部分在内存是连续的,对应的含义如下:
:4 字节;用来记录整个压缩列表占用的内存字节数。 :4 字节,用来记录压缩列表表尾节点(最后一个 entry)距起始地址有多少字节,即偏移字节数。 :2 字节,记录了包含的节点数量,即 entry 的个数。当 entry 个数小于 2^16-1(65535)时,这个属性值就是压缩列表包含的节点个数;而当这个值等于 2^16-1 时(该字段只有 2 字节,16bit,即能表示的最大值,所有位数都为 1),节点数量需要遍历整个压缩列表才能得出。 :长度不定,用来存放实际要存储的数据项,有对应的结构,下面会再介绍。 :1 字节,固定为 255,用来标记压缩列表的末端。

:1 字节或 5 字节;用来记录前一个节点的长度,前一个节点长度小于 2^8-2(254)字节时,那么该属性长度为 1 字节,前节点的长度就保存在这一个字节中;如果前一个节点长度大于等于 254 字节,那么该属性长度为 5 字节,第 1 字节固定为 0xFE(十进制 254),而后面 4 个字节则用来存储前节点长度。(1 字节 8 位,最高不是能用来代表 255 吗?为啥是 254?因为 属性固定值为 255,要与其区分开) :1 字节、2 字节或 5 字节;用来记录节点 content 属性所保存数据的类型以及长度。 :长度不定;负责保存节点的值,可以是字节数组,也可以是整数。
压缩列表?“内存连续的双向链表”!
看到了上面这些属性,你可能不是很懂,但它其实算是一个“内存连续的双向链表”。
(自己试着归纳,如有错误还请评论区纠正~)
为什么这么说?你想想看双向链表的几个属性:
- 头节点 head
- 尾节点 tail
- 节点 next 指针
- 节点 last 指针
而这些我们根据上面的属性都可以得出来:
- 头节点:元素前三个属性一共固定占 10 字节,马上能找到第一个节点的地址。
- 尾节点:根据
属性,即尾结点的偏移字节数,直接可以得到最后一个节点的起始位置。 - entry 的 next 节点:因为内存连续,又知道
和 的属性值, 又包含 的长度,所以可以得到下一节点的起始位置。 - entry 的 last 节点:因为内存连续,又知道
属性值,即前一节点的长度,所以可以得到上一个节点的起始位置。
为什么要用“内存连续的双向链表”啊?当然是为了实现压缩的特点了。
压缩体现在哪里?
- 首先可以明确压缩列表用连续内存来实现,不会造成数据之间空闲的内存碎片,已经体现了压缩的概念。
- 还有的就是上面属性值的长度,比如
属性,已经尽可能占用最少的内存来存储长度了,当 1 字节不够时才用 5 字节来存储数据,像这样灵活的属性长度,里面还有许多。
连锁更新
既然是内存连续的,那肯定又牵扯到一个老问题:牵一发动全身
假如我要新添加一个节点,肯定要执行空间重分配操作,而且因为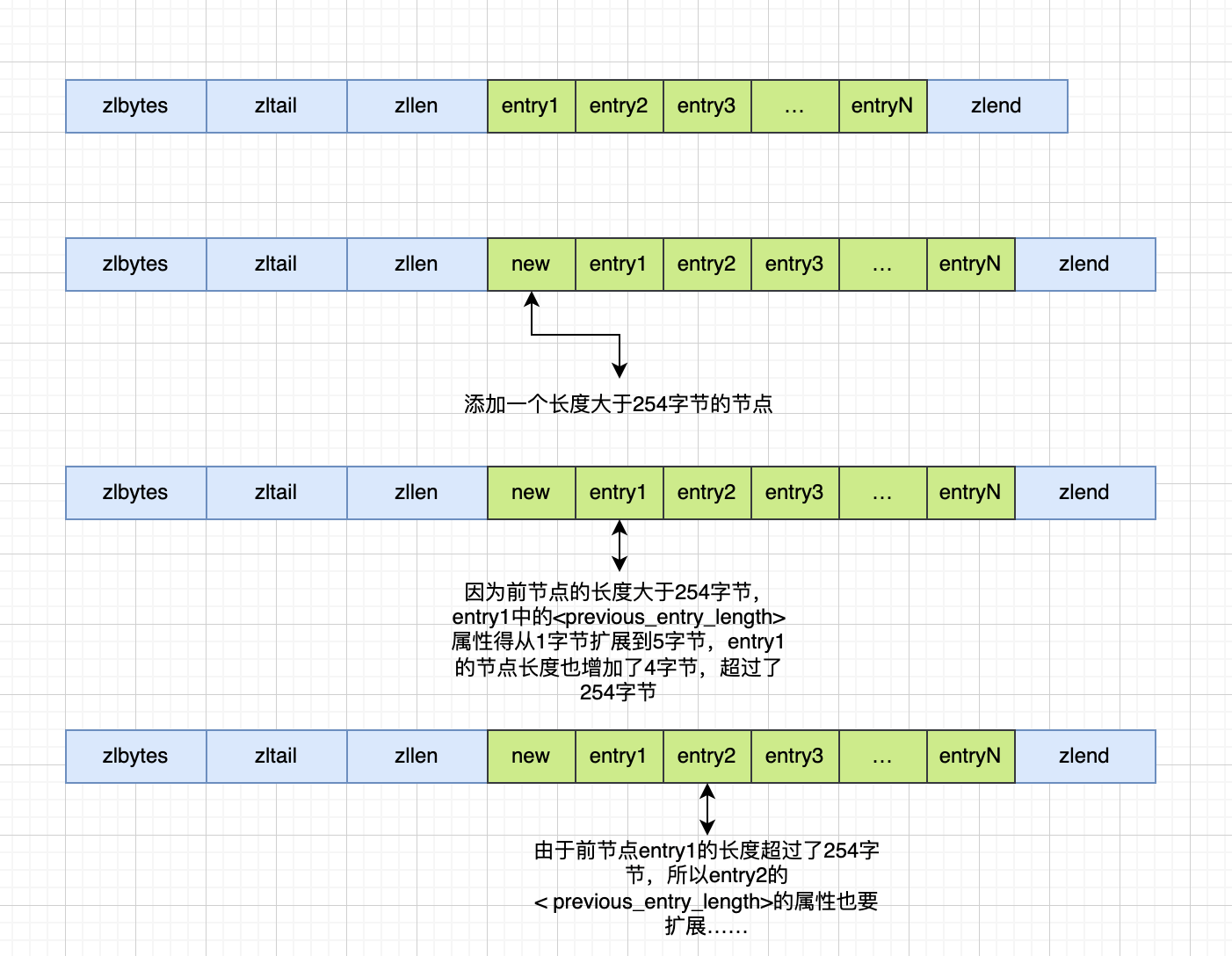
删除操作也会引发这样的连锁更新,在最坏的情况下需要对压缩列表执行 N 次空间重分配操作。
但要注意的事,尽管连锁更新的耗时很长,但其实真实发生的概率是很低的:
上面我们是假设每个节点都在 250~253 字节之间,实际上,这种情况几乎没有。
因为这些,ziplist 的一些操作命令的复杂度仅为 O(N),我们可以放心使用,不用过分担心上述假设引起的性能问题。
写在最后的最后
我是苏易困,大家也可以叫我易困,一名 Java 开发界的小学生,文章可能不是很优质,但一定会很用心。
又一个转眼,清明假期过去了,作为一个假期就躺着的社畜,表示自己的内驱力还是不够,不过我现在想得还是能出去转转,以前一直期盼着居家办公,但真的居家办公后还是闷得发慌,而且加上最近发生一些不开心的事情,确实需要时间来整理心情。
但一码归一码,博文更新还是不能落下,redis 的基本数据结构不知道后面还会不会继续,因为还有两个数据结构 quicklist 和 intset 我觉得没什么特别的地方,可能会从 redis 别的方面再入手写一点东西吧,也有可能会开启新的篇章吧~现在还不好说,大家就一起加油吧~💪






