
Java线程池配置由繁至简,找到适合自己的天命线程池(二)
前提知识 🧀
上一篇我们简单介绍了下线程池的一些基本内容,不清楚或者想回顾的同学可以点进主页里查看,或者后面把链接 🔗 贴在评论里。我们这篇主要来解决上一篇最后提出的问题:根据项目,自己来设置合适的参数。这个合适到底要怎么来定义?且往下看。
任务队列 workQueue 和饱和策略 handler 什么时候登场?
首先这里有几道经常考的线程池面试题:
- 简单介绍下线程池,核心数从 corePoolSize 到 maximumPoolSize 的变化过程?
- 线程池在什么时机会执行饱和策略?
- 当线程池的任务队列满之后,就会执行对应的饱和策略吗?
这些问题其实说到底都是在考线程池的执行步骤,当你弄懂这些时机和条件后,我相信你可以融会贯通整套流程。
我们这里先引入流程图看一下: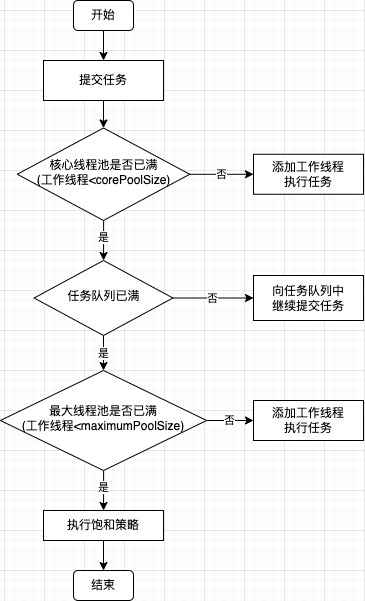
只看流程图可能不容易理解,我们下面用一个示例来演示一下整个流程:
首先我们假设几个参数,corePoolSize 核心线程为 5,maximumPoolSize 最大线程数为 10,workQueue 任务队列的容量为 20,还需要用 activeCount 来表示正在工作的线程(下面简写为工作线程),为了兜底,所以假设任务一直在添加,由于很耗时,程序 hold 不住,一直到执行饱和策略的环节。
- 假设不断地有任务进来,程序就会增加工作线程来处理任务,即 activeCount 增加,会一直增加到 corePoolSize,直到满足第一个条件“核心线程池已满”,即 activeCount=corePoolSize=5。
- 这时再追加任务,程序就会把任务放进任务队列 workQueue,工作线程处理完当前任务,就会按 FIFO 先入先出的顺序,从任务队列 workQueue 里拿出任务继续做;随着任务的放入,workQueue.size()会逐渐增大,一直到满足第二个条件“任务队列已满”,即 workQueue.size()=20,activeCount 此时仍为 5。
- 再继续追加任务,程序就会在 corePoolSize 的基数上继续增加工作线程,即 activeCount 从 5 开始增加,一直到满足第三个条件“最大线程池已满”,即 activeCount=maximumPoolSize=10。
- 此时我们看一下参数值,activeCount=maximumPoolSize=10,workQueue.size()=20,能满的已经全满了,表示程序已经达到了最大的上限,后面再追加的任务就会去执行饱和策略。
饱和策略有哪些?哪个更适合我?
我们先来回顾下饱和策略的意义——由于达到线程边界和队列容量而阻塞执行时使用的处理程序。
可以简单地用一句话来解释:任务队列满 & 工作线程数已经增加到最大核心数,此时再新增进任务,便会对任务执行对应的处理。
AbortPolicy
Abort->退出、终止;满足条件时会直接抛出 RejectedExecutionException 异常,它也是 ThreadPoolExecutor 默认的饱和策略;但同时由于他的简单粗暴,程序可能会因此中断,所以虽然是默认的饱和策略,但如果要用,务必做好异常处理。
CallerRunsPolicy
满足条件时,会直接调用当前主线程去执行任务,比如你在 main 方法执行了线程池,策略的缺点就是可能会阻塞主线程,影响性能。
DiscardPolicy
�Discard->丢弃,抛弃;这个是最简单粗暴的饱和策略,直接扔掉,满了之后再来的任务统统扔掉!对一些不重要,或者时效性比完整性优先级高的任务还是挺好用的,但如果你对任务的完整性要求高,不建议使用。
DiscardOldestPolicy
� 比上个策略多了一个 oldest,意思就是FIFO 先入先出,当满足条件时,会优先丢弃队列里最旧即最早的任务数据,所以同样的,如果你对任务的完整性要求高,不建议使用。
这么比较下来,相信你心里已经有了答案: 1.如果你对任务的完整性要求很高,一条数据都不能丢,比对性能的要求高,那合适的选择就是 CallerRunsPolicy。 2.如果你对性能要求很高,数据少或多都还能接受,就可以选择其他三个饱和策略,丢弃或者对异常进行处理。
你可能会说:性能和完整性,我全都要!
那怎么办呢?有什么办法吗?
我的答案是:当然有,它既然叫饱和策略,肯定是满足条件后才会走到这一步,相当于最后的保底措施,所以在一定情况下,假如根据程序配好了其他参数,是根本不会走到饱和策略这一步的,我们要做的就是:调整好其他参数,饱和策略是最后的底牌,尽量不要触发。
核心线程数和最大线程数到底设置多少?
从上面一系列介绍中,我们知道任务队列和饱和策略都有了推荐,但其实大家伙最关心也是最疑惑的就是核心线程数和最大线程数的设置。
你可能在这之前翻过很多文章,有人说设置为服务器核心数 N,有人说应该是服务器核心数 N+1,有人说要判断是 I/O 密集型就 2N,计算密集型的话就 N+1,都很有理论依据,我曾经也为这个所苦恼。
其实连带的还有一些问题,比如每台服务器的情况不一样,有的可能同时跑得有 tomcat,有的可能还有有别的服务,这个时候上面的理论配置是否还适合我们?
在经过翻查无数次的资料与文章后,一篇美团在 2020 年发布的名为《Java 线程池实现原理及其在美团业务中的实践》的文章让我眼前一亮:既然参数在每个服务器上都不确定,那我改成动态配置的不就可以了吗?不够我就加,多了我就减。
可惜美团只提供了思路,并没有把代码开源出来(行了吧,还要啥自行车?
但是并不妨碍网上的大佬多,已经有个人开发者把这套逻辑整理出来并开源,没错,我也已经上车了,真香!如果你想了解,可以搜索“动态线程池配置”这些关键词,我在这里就不打广告了。
JOJO!这是我最后的项目示例了!
拿我自己的经历举个例子,阿里云 4 核 8G 的机器,单机任务的峰值 QPS 大概为 2000 左右,虽然不高,但由于线程池执行的任务都是从别家服务器获取响应,所以容易堆积,设置了最大超时时间 200ms。
最早一版的配置是 5/16/2000(corePoolSize/maximumPoolSize/workQueue.capacity),无奈不到高峰期就报警。
后赶紧调整参数到 8/16/2000,当时倒是不报警了,但在后面增加了策略配置后(即并发任务量增加)又出现了报警。
最后调整到 16/32/2000,依旧报警,没错,不光 N+1、2N,都已经 N^2,它还是报警。
这时我意识到很多情况,可能是网络问题,可能是因为服务还有其他的线程池,也可能是已经到了线程池性能的瓶颈,所以并没有对参数进行进一步的调整。
但玄学的事情发生了:在这波报警后,后面就再也没有发生过报警了,也观察了线程池日志,发现工作线程 activeCount 最大也只到了 16,2000 容量的任务队列也只用到几十到一百多个,一切好像都归于了平静,于是参数也没有再进行修改了,似乎已经找到了最合适的参数。
好的,如果你看到这里,那么现在这个例子已经是你的了。
最后的建议
- 在面试时,记住八股文,知道 I/O 密集型和计算密集型的理论值场景,但在跟面试官讲述时可以加上自己项目的例子,实在没有就可以说上面这个。
- 在实际的项目运用中,结合项目情况,最好加上动态线程池配置。
写在最后的最后
其实这篇和上篇是一口气写下来,但因为篇幅原因分开,所以建议一定要连贯地看下来。
在我看来如果能够将两篇内容都 get 到,对你使用线程池和跟面试官掰扯一些基本题,都会有一定的帮助;如果先看完这两篇,那么我推荐你接着去看美团官方的文章,我觉得算是一记加强针。
其实线程池可掰扯的东西只有这些吗?其实文章很多地方都没有点透,甚至有些疑问,比如:饱和策略只有这几个吗?有没有别的?我可以马上回答你:有!别的框架甚至都把线程池玩出了花,比如像 dubbo 的饱和策略就是会新建一条新线程来执行任务、比如 tomcat 的线程池核心数由 core 到 max 变化条件就跟 jdk 的不一样,总而言之,也是每个框架用了最符合自己的逻辑,如果有下一篇的话,可能就会唠唠这些吧,嘻嘻~
如果你能有所收获,那么我会很开心的~如果可以点赞评论收藏分享,那么我的动力会更足的,谢谢大家 ~







