
Redis数据结构详解(2)-redis中的字典dict
前提知识 🧀
字典,又被称为符号表(symbol table)或映射(map),其实简单地可以理解为键值对 key-value。
比如 Java 的常见集合类 HashMap,就是用来存储键值对的。
字典中的键(key)都是唯一的,由于这个特性,我们可以根据键(key)查找到对应的值(value),又或者进行更新和删除操作。
字典 dict 的实现
Redis 的字典使用了哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,每个节点也保存了对应的键值对。
Redis 的字典 dict 结构如下: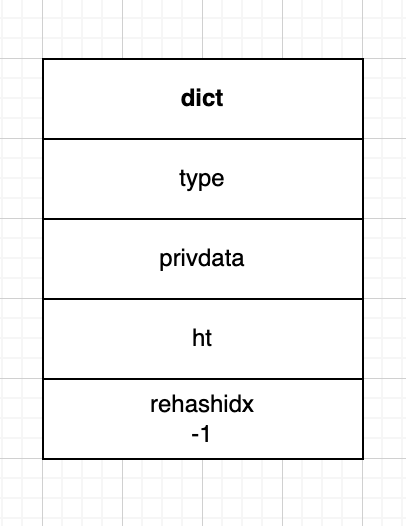
1 | typedef struct dict { |
我们重点关注两个属性就可以:
- ht 属性:
可以看到 ht 属性是一个 size 为 2 的 dictht 哈希表数组,在平常情况下,字典只用到 ht[0],ht[1] 只会在对 ht[0] 哈希表进行 rehash 时才会用到。
- rehashidx 属性:
它记录了 rehash 目前的进度,如果现在没有进行 rehash,那么它的值为-1,可以理解为 rehash 状态的标识。
下图就是一个普通状态下的字典: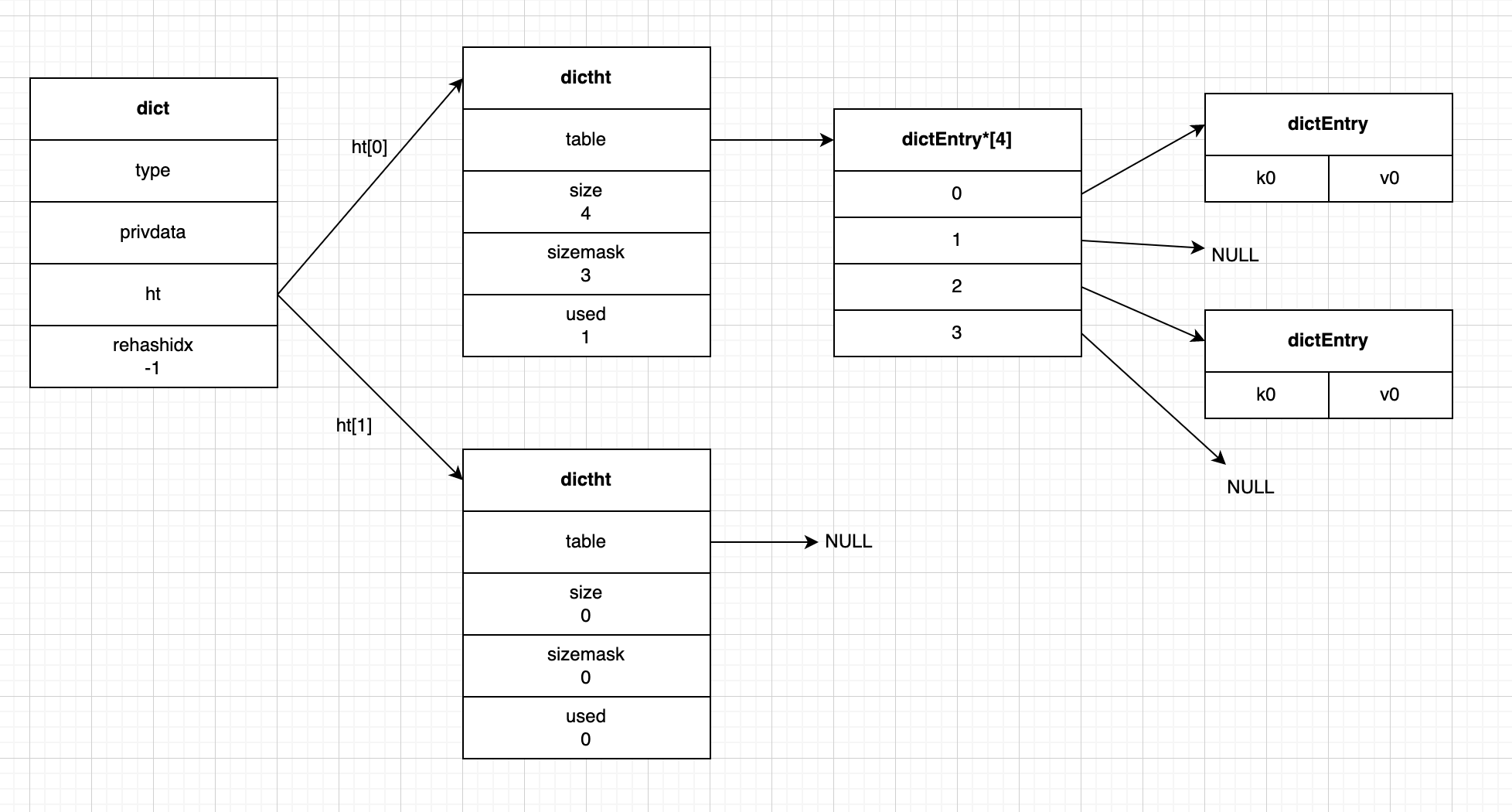
实际的数据在 ht[0] 中存储;ht[1] 起辅助作用,只会在进行 rehash 时使用,具体作用包括 rehash 的内容我们会在后面进行详细介绍。

哈希算法定位索引
PS:如果你有 HashMap 的相关知识,知道如何计算索引值,那么你可以跳过这一部分。
假如我们现在模拟将 hash 值从 0 到 5 的哈希表节点 放入 size 为 4 的哈希表数组 中,也就是将包含键值对的哈希表节点放在哈希表数组的指定索引上。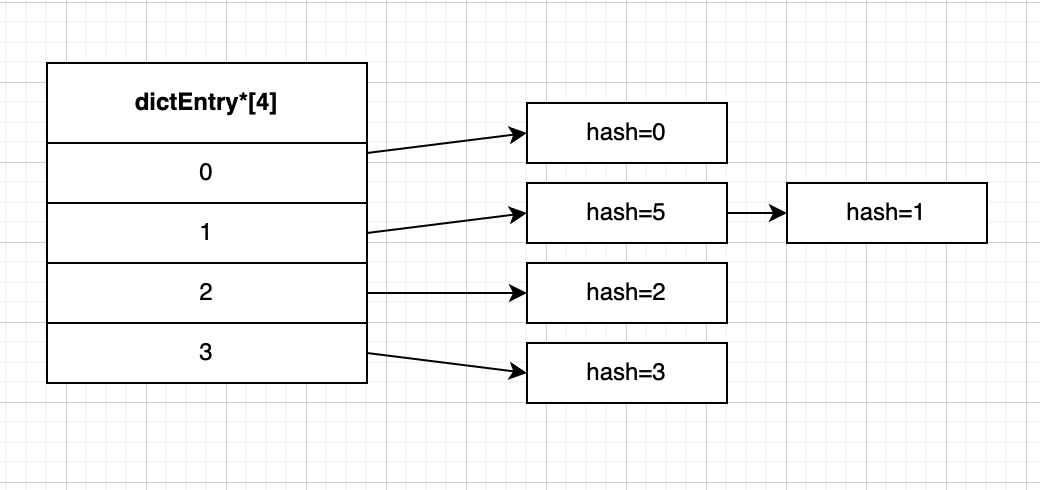
对应索引的计算公式:
index = hash & ht[x].sizemask
看不懂没关系,可以简单的理解为 hash 值对哈希表数组的 size 值求余;
比如上面 hash 值为 0 的节点,0 % 4 = 0,所以放在索引 0 的位置上,
hash 值为 1 的节点,1 % 4 = 1,所以放在索引 1 的位置上,
hash 值为 5 的节点,5 % 4 = 1,也等于 1,也会被分配在索引 1 的位置上,并且因为 dictEntry 节点组成的链表没有指向链表表尾的指针,所以会将新节点添加在链表的表头位置,排在已有节点的前面。
我们把上面索引相同从而形成链表的情况叫键冲突,而且因为形成了链表!那么就意味着查找等操作的复杂度变高了!
例如你要查找 hash=1 的节点,你就只能先根据 hash 值找到索引为 1 的位置,然后找到 hash=5 的节点,再通过 next 指针才能找到最后的结果,也就意味着键冲突发生得越多,查找等操作花费的时间也就更多。
如果解决键冲突?rehash!
其实 rehash 操作很好理解,可以简单地理解为哈希表数组扩容或收缩操作,即将原数组的内容重新 hash 放在新的数组里。
比如还是上面的数据,我们这次把它们放在 size 等于 8 的哈希表数组 里。
如下图,此时 size = 8,hash 为 5 的键值对,重新计算索引:5 % 8 = 5,所以这次会放在索引 5 的位置上。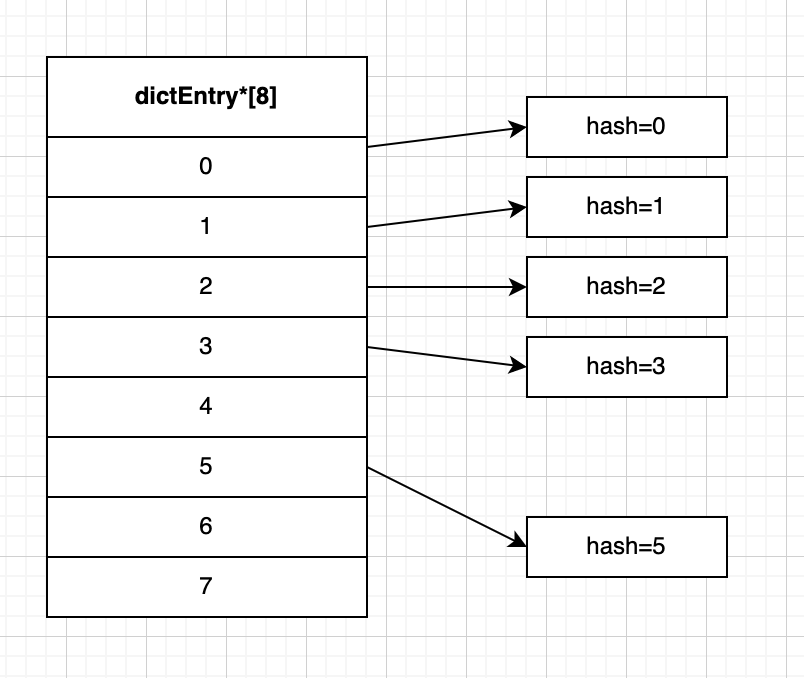
那么假如我们还要找 hash=1 的节点,因为没有键冲突,自然也没有链表,我们可以直接通过索引来找到对应节点。
可以看到,因为 rehash 操作数组扩容的缘故,键冲突的情况少了,进而我们可以更高效地进行查找等操作。
触发 rehash 操作的条件
首先我们先引入一个参数,叫做负载因子(load_factor),要注意的是:它与 HashMap 中的负载因子代表的含义不同;在 HashMap 里负载因子 loadFactor 作为一个默认值为 0.75f 的常量存在,而在 redis 的 dict 这里,它是一个会动态变化的参数,等于哈希表的 used 属性值/size 属性值,也就是 实际节点数/哈希表数组大小。假如一个 size 为 4 的哈希表有 4 个哈希节点,那么此时它的负载因子就是 1;size 为 8 的哈希表有 4 个哈希节点,那么此时它的负载因子就是 0.5。
满足下面任一条件,程序就会对哈希表进行 rehash 操作:
- 扩容操作条件:
- 服务器目前没有执行 BGSAVE 或者 BGREWRITEAOF 命令,负载因子大于等于 1。
- 服务器目前正在执行 BGSAVE 或者 BGREWRITEAOF 命令,负载因子大于等于 5。
- 收缩操作条件:
- 负载因子小于 0.1 时。
BGSAVE 和 BGREWRITEAOF 命令可以统一理解为 redis 的实现持久化的操作。
- BGSAVE 表示通过 fork 一个子进程,让其创建 RDB 文件,父进程继续处理命令请求。
- BGREWRITEAOF 类似,不过是进行 AOF 文件重写。
渐进式 rehash?rehash 的过程是怎么样的?
首先我们知道 redis 是单线程,并且对性能的要求很高,但是 rehash 操作假如碰到了数量多的情况,比如需要迁移百万、千万的键值对,庞大的计算量可能会导致服务器在一段时间里挂掉!
为了避免 rehash 对服务器性能造成影响,redis 会分多次、渐进式地进行 rehash,即渐进式 rehash。
(可以理解粗略地理解为程序有空闲再来进行 rehash 操作,不影响其他命令的正常执行)
对哈希表进行渐进式 rehash 的步骤如下:
- 首先为 ht[1] 哈希表分配空间,size 的大小取决于要执行的操作,以及 ht[0] 当前的节点数量(即 ht[0]的 used 属性值):
- 扩展操作,ht[1]的 size 值为第一个大于等于 ht[0].used 属性值乘以 2 的 2^n
- 收缩操作,ht[1]的 size 值为第一个小于 ht[0].used 属性值的 2^n
(有没有很熟悉,其实跟 Java 中的 HashMap、ConcurrentHashMap 操作类似)
- 将哈希表的 rehashidx 值从-1 置为 0,表示 rehash 工作开始。
- 节点转移,重新计算键的 hash 值和索引值,再将节点放置到 ht[1]哈希表的对应索引位置上。
- 每次 rehash工作完成后,程序会将 rehashidx 值加一。
(这里的每次 rehash 就指渐进式 rehash)
- 当 ht[0]的所有节点都转移到 ht[1]之后,释放 ht[0],将 ht[1]设置为 ht[0],并在 ht[1]新创建一个空白的 hash 表,等待下次 rehash 再用到。(其实就是数据转移到 ht[1]后,再恢复为 ht[0]储存实际数据,ht[1]为空白表的状态)
- 最后程序会将 rehashidx 的值重置为-1,代表 rehash 操作已结束。
进行渐进式 rehash 的时候会影响字典的其他操作吗?
因为在进行渐进式 rehash 的时候,字典会同时用到 ht[0]和 ht[1]这两个哈希表,所以在这期间,字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表进行;而进行添加操作时,会直接插入到 ht[1]。
比如查找一个键时,程序会先在 ht[0]里面查找,没找到的话再去 ht[1]里进行查找。
搜资料的时候还看到好多评论,都对逻辑产生了疑问,还举了例子说有问题,但我仔细看了下,其实都是忽略了删除和更新都会在两个哈希表进行的前提条件。

写在最后的最后
我是苏易困,大家也可以叫我易困,一名 Java 开发界的小学生,文章可能不是很优质,但一定会很用心。
距离上次更新都过去了好久,一是因为上海的疫情有点严重,一直没静下心来好好整理知识,还有就是发现自己得先很好地消化完知识才能够整理出来,不然其实各方面收获不大;所以后面也会自己先认真消化后再整理分享,不会追求速度,但会认真总结整理。
因为疫情要一直封到 4 月 1 号,我们小区还有 1 例阳性,更不知道到什么时候了,每天早上也要定闹钟抢菜,但还抢不到,因为没有绿叶菜的补给,我感觉已经得口腔溃疡了,还好买到了维 C 泡腾片,感觉可以稍微缓缓。
疫情掰扯这么多,其实我和大家一样,我有想吃的美食,有想去的地方,更有马上想见到的人,所以最后还是希望疫情能够赶紧好起来~







