
Redis数据结构详解(3)-redis中的“排序好手”(跳表skiplist)
前提知识 🧀
自从通过博客开始记录学习内容、整理知识,整个人变得比以前更积极了,虽说本质是为了记录和整理,但不免对各大博客网站的阅读数和点赞评论数关心(虽然到现在还少得可怜哈哈哈),有的博客网站还有自己专属的积分值,甚至还有排行榜,我偶尔也会点开看看,幻想自己能出现在上面~(嘻嘻~梦里什么都有)
问:那么这个排行榜应该怎么实现呢?(强行应题!)
答:简单!数据库用一个表来维护,按积分值字段大小排序不就行了~
确实可行,但因为网站的并发量高,需要快速响应,就要借助缓存来实现,而 redis 中刚好有一个基本数据结构符合这个要求,那就是Sorted set(有序集合),它跟 Set(集合)一样不能有重复的元素,但是多了排序的功能,而且是自动排序,不需要维护的,也就是你添加或更新元素,底层自动就帮你排序了。所以当你需要一个有序且不重复的集合列表,那么 Sorted set 将是一个不错的选择。
Sorted set 的底层实现用到了属于 redis 用到比较有代表性的数据结构——跳表 skiplist,也是我们今天要说的主要内容,它是如何在 redis 中起到了排序的作用,又是怎么实现的呢?我们从头梳理一下~
中华文化博大精深
我们经常说到这句话:中华文化博大精深;但是有时在理解意思不当也会产生反效果。比如跳表,全称是跳跃列表(摘自百科),如果你没有看到跳表的英文单词skiplist,可能要误会,此跳跃(skip)非彼跳跃(jump),不是双脚离地的跳起,而是“跳过、省略”的意思,所以我个人觉得翻译为“跳越列表”可能更适合一点,不过也不必纠结这个,相信明白了跳表 skiplist 的英语原意,会更好地帮你继续往下了解跳表。
排序,你会想到什么?
我们先从最基础的数据结构来想:
数组 ❎
数组是在内存上连续的,假如你对要维护排序的元素有新增、更新、删除的操作,那么将“牵一发而动全身”,势必需要做大量的内存删除或者移动操作;所以除非是要维护一个固定不变的元素集合,其他情况我们就不用考虑数组了,所以 pass。
链表 ✅
链表就不存在上面的情况,而且链表的特点就是用来存储线性表的数据结构;新增、更新、删除等操作无非也就是改变指针指向的地址,是个不错的选择。
哈希表 ❎
哈希表其实不是有序的,在哈希表上只能做单个 key 的查找,不适合做范围查找,所以也 pass 掉。
树 ✅
树其实也是一个用来排序的优质选择,但从结果来看,redis 并没有取用它,原因我们先按下不表,后面会详细解释。
普通链表能满足需求吗?跳表对它做了什么优化?
我们先来看一个普通的有序链表:
假如我现在要添加一个 新元素 18
那么我只能先从头结点开始,通过 next 指针找到第一个 元素 2,然后再通过 next 指针找到下一个 元素 3,如此反复,直到我们找到第一个大于等于要添加的元素,即 元素 19,它比 18 大,所以我们应该把 元素 18添加在 元素 19之前,通过8 个指针(简略为数红箭头个数)寻址到最后结果。
由此可见:链表越长,插入的位置越靠后,那么耗费的时间就更多,时间复杂度为 O(n)。
总感觉可以优化呢!又要提到这句话了:
众所周知,redis是一个追求性能的程序。
这里插入一个小知识:
在 30 多年前的 1990 年,威廉·普发明了跳跃列表(跳表),从百科摘下发明者威廉·普对跳表的评价:
跳跃列表是在很多应用中有可能替代平衡树而作为实现方法的一种数据结构。跳跃列表的算法有同平衡树一样的渐进的预期时间边界,并且更简单、更快速和使用更少的空间。
奈斯!通过这个评价我们不光对跳表有个大致的了解,好像还顺便牵扯了一道常见的相关面试题。
作者说跳表简单?哪里简单?你说说看!
跳表跳表,之所以叫跳表,就是因为它可以跳~(不是
是因为跳表可以通过节点的跃迁更快地找到目标值。
我们沿用上面的数据,但是直接换用跳表的数据结构举个栗子 🌰:
直观来看,一些元素似乎多了一层,但我们不知道干嘛的,不过先别急,我们按照这个结构试着添加新元素 18
之前我们是从第一层开始的,但这次我们从第二层,也就是 L2 节点开始,通过 next 指针跳过了 元素 2直接指向 元素 3,再指向 元素 7,一直到比 元素 18大的 元素 19,然后通过 backward 指针找到前一个 元素 17,元素 18又大于它,所以我们最终把元素添加到这里,通过5 个指针(简略为数红箭头个数)寻址到最后结果。
相比之前简单链表要通过 8 个指针来寻址,跳表的复杂度低了一点。不过我们还不满足,我们这次把部分元素的层数增加到 3 层再看一下。
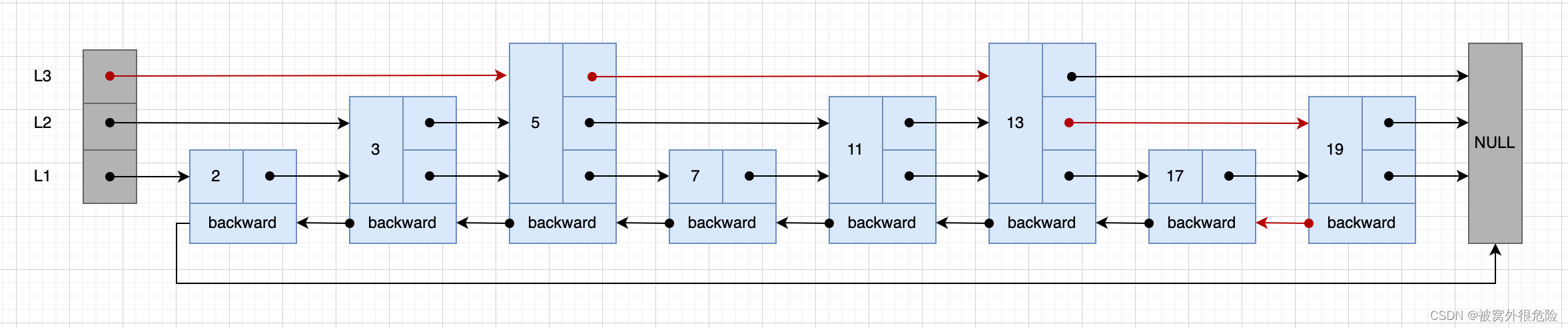
这次又少了,通过4 个指针(简略为数红箭头个数)就可以寻址到最后结果。
跳表 skiplist 的寻址逻辑可以简单地概括为:
从最高层开始寻址,当前节点的 next 指针如果指向 null 的话就下降一层,next 指针指向的下一个元素值如果小于查找值,就继续走,如果大于的话就调用 backward 后退指针找前一个元素再比较,直到找到对应的位置。
那元素分值 score 会不会相同呢?
会,这时候就会按数据 obj 的字典序排序,可以简单理解优先级为 0~9、A~Z、a~z。
你有没有发现,上面的过程有点类似于二分查找,或者说 n 分查找,理想状态下可以 把时间复杂度从原来的O(n)降低到O(log n)。
跳跃表节点详解
首先我们看下跳跃表节点结构定义:
1 | typedef struct zskiplistNode { |
看到具体的跳跃表节点结构,我们就知道多的层是哪里来的了。
我们上面的举例是很理想的状态,层数从 1 到 n 循环出现,但是假如你对数据有修改,比如新增或删除,如果还要遵循“层数从 1 到 n 循环出现”的原则,那就其实就跟上面说的数组一样 —— 牵一发而动全身,还需要维护层数,得不偿失。
于是乎,redis 采用了一个有趣的方法来设置节点的层数。
- 首先肯定所有节点都有第一层指针。
- 那么每次有新增节点时,要不要继续往上加层数呢?我们抛硬币吧,只要出现正面就一直加,直到出现反面就停止。
- 最高加到 32 层。
当然,程序不可能抛硬币,只是举个栗子 🌰,实际是通过 while 循环实现的,而且增加层数的概率是 1/4,并不是抛硬币的非正即反。
根据上面的概率,我们可以得出:
- 节点层数恰好为 1 的概率为 $\frac{3}{4}$
- 节点层数恰好为 2 的概率为 $\frac{1}{4}\cdot\frac{3}{4}$
- 节点层数恰好为 3 的概率为 $\frac{1}{4}\cdot\frac{1}{4}\cdot\frac{3}{4}$
- ……概率分布……
因为一层需要一个指针,那么求一个节点的平均指针数如下:
$$1\cdot\frac{3}{4}+2\cdot(\frac{1}{4}\cdot\frac{3}{4})+……+n\cdot(\frac{1}{4})^{n-1}\cdot\frac{3}{4}=\frac{3}{4}\cdot\sum_{i=1}^{+\infty}\cdot{n}\cdot(\frac{1}{4})^{n-1} = \frac{4}{3}$$
经过一系列计算可以得出每个节点所包含的平均指针数大约为 1.3 个。
现在我们回收伏笔,在最前面我们提到 redis 最终并没有采用树这样的结构,其中一个原因就跟指针个数有关:
(不清楚树的数据结构也没关系,只需要知道树的指针固定有两个,左子树指针 和 右子树指针)
跳表节点的平均指针数是 1.3 个,而树的指针数固定为 2 个,指针又占用一定内存,显然跳表比树是用到更少的内存,redis 是基于内存的操作,瓶颈最有可能就是内存大小和网络带宽,所以跳表比起树更节约内存一点。
那么 Redis 还因为啥用 skiplist 而不用树结构?
其实对于这个问题,redis 的作者给过答案:
There are a few reasons:
- They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
- A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
- They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
概括来说就是下面几点:
- skiplist 不是很占用内存,平均节点指针数小于树(上面证明过)。
- skiplist 可以很好的实现范围查找(指查找大小在指定两个值之间的所有节点,例如 ZRANGE 命令),树要比跳表操作复杂,花费时间更多。
- skiplist 好实现!树还牵扯子树的调整,逻辑复杂,skiplist 从算法实现难度上比树要简单得多。
当你遇到了这道面试题,面试官还说你不对时,你就可以理直气壮地告诉他这是 redis 作者说的。
写在最后的最后
我是苏易困,大家也可以叫我易困,一名 Java 开发界的小学生,文章可能不是很优质,但一定会很用心。
紧赶慢赶还是把跳表赶出来了,说实话,几个月前我还对跳表一无所知,只是知道 redis 用到,而且是个经常问到、且有代表性的数据结构,努力消化揉碎后自己也收获良多,如果大家也能有所收获,那么我会非常开心的~
坚持更文还是挺有挑战的,希望也能一直坚持下去,趁着疫情居家办公有时间多看看书,不能让自己懒惰起来,加油加油,大家也一起加油!最后还是希望疫情能早点好起来,大家可以恢复正常的生活~






