
为什么JVM要用到压缩指针?Java对象要求8字节的整数倍?
前言
前两天在一个帖子中看到一道面试题:堆内存超过32G时,为什么压缩指针失效?
之前没有了解过这方面的知识,于是开始 google 起来,但当我翻看了不下一页的帖子,我都仍然没有搞懂,因为好多答案给我的感觉更像是:因为堆内存超过32G,压缩指针会失效,所以堆内存超过32G时,压缩指针会失效。
我:???
本着有问题搞不懂就吃不下冰激凌的原则,我决定搞清楚这个问题。
32 位和 64 位
首先我们都知道知道操作系统有 32 位操作系统(别名 x86 )和 64 位操作系统(别名 x86-64 或 x64),相对的 JVM 也分为 32 位和 64 位。
什么?你没注意过?
如何知道现在自己使用的 JVM 是 32 位还是 64 位?
命令行输入:java -version
如果你是 64 位的话,会出现 64-Bit 这样的内容:
1 | java version "1.8.0_202" |
如果你是 32 位的话,则没有相关的内容:
1 | java version "1.8.0_211" |
32 位操作系统只可以运行 32 位的 JVM,64 位操作系统则都可以运行(有点类似兼容老版本)。
那我应该如何选择多少位的 JVM 呢?
32 位 JVM 的寻址空间只有 4G(2^32),也就是你的 java 进程最大只能使用4G 内存(因为有其他开销,实际远小于 4G);而 64 位 JVM 的寻址空间最大有 2^64,差不多可以理解为无限大。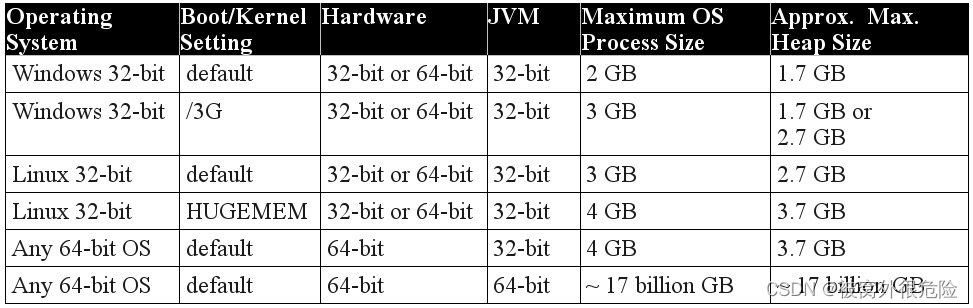
(不同操作系统和 JVM 对应的 进程最大内存 和 最大堆内存)
(Approx:大概,approximately 的缩写)
64 位的 JVM 听起来是升级版,性能要比 32 位的 JVM 要高吧?
其实恰恰相反,64 位 JVM 的寻址空间更大了,但是会带来性能的损耗;同样的应用,运行在 64 位 JVM 上 比起 运行在 32 位 JVM 上 会有 0~20%的性能损耗(取决于应用里面指针的数量)。
其实从名字上我们可以就可以区分,64 位 JVM,他的每一个 native 指针都占用 64 位(即 64bit,也就是 8 字节)。32 位 JVM 则只有 4 字节。加载这些额外的字节也自然会影响内存的占用。
铺垫这么多,指针的寻址原理奉上
假如我们这里有 3 个对象 A、B、C,他们的大小分别为 8、16、8 字节(为什么假设这几个值,我们先按下不表),并且在内存中连续存储,为更好理解,我们简化为下图:
指针用 内存位置 来标记对象在内存中的位置:
A:00000000 00000000 00000000 00000000 (十进制表示:0)
B:00000000 00000000 00000000 00001000 (十进制表示:8)
C:00000000 00000000 00000000 00011000 (十进制表示:24)
从上面可以看出 32 位的指针,满打满算也只能存储 2^32,约 4GB 的内存地址。
如果是 64 位的指针,就能表示 2^64,上面说的可以理解为无限大,如果你有听过 国际象棋盘与麦粒 的故事就知道,它肯定能满足需求,甚至感觉还有点浪费。
回归题目,压缩指针的引入。
既然 64 位指针用来存储太浪费了,有什么更好的办法可以在 32 位的限制下表示更多的内存地址吗?
这时,我们发现对象 A、B、C 大小都是 8 字节的整数倍,即 8 是他们对象大小的最大公约数!
我这边就不卖关子,直接说答案,我们可以借助索引来标识。
用 8 位内存地址偏移量 代表 1 索引
那么 A 的位置就可以标识为 索引 0,B 为 索引 1,C 为 索引 3。

指针用 索引 来标记对象在内存中的位置:
A:00000000 00000000 00000000 00000000 (十进制表示:0)
B:00000000 00000000 00000000 00000001 (十进制表示:1)
C:00000000 00000000 00000000 00000011 (十进制表示:3)
加入索引这一概念是为了方便理解;实际上 JVM 是通过读取时左移 3 位,存储时右移 3 位来完成的。
也就是说原本可表示 4GB 的内存地址,因为 1 索引表示 8 个内存地址偏移量,现在可以表示最高存储 32GB 的内存地址了。
伏笔回收:Java 对象的大小为什么必须是 8 字节的整数倍?
上面的对象 A、B、C 我们假设的大小是 8 字节、16 字节、8 字节;共同点你可能发现了,他们都是 8 字节的倍数,其实 Java 对象的大小就必须是 8 字节的整数倍,如果没有这个条件,上面说的索引说法也不成立。
当然除了为了支持上面这些功能外,另外还有的就是因为现在大多数计算机都是高效的 64 位处理器,顾名思义,一次能处理 64 位的指令,即 8 个字节的数据,HotSpot VM 的自动内存管理系统也就遵循了这个要求,这样子性能更高,处理更快。
JVM 如何保证 Java 对象的大小都是 8 字节的整数倍?
用一个普通的 Java 对象举个简单的栗子 🌰
在 JVM 中,Java 对象保存在堆中,由三部分组成: 1.对象头 (Object Header) 2.示例数据(Instance Data) 3.对齐填充(Padding)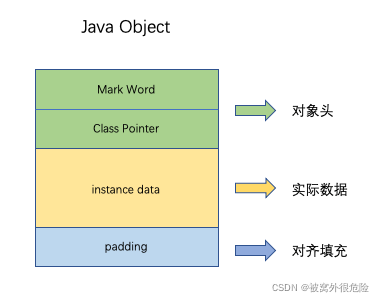
如果你还不了解的话也没关系,我们讨论的只牵扯到最后一个部分,也就是 对齐填充。
对象可以有对齐填充,也可以没有;如果一个对象的前两部分所占大小不是 8 字节的整数倍,比如 12 字节,那么对齐填充会以此来填充对象大小到 8 字节的整数倍,即对齐填充占 4 字节,java 对象一共 16 字节。
对齐填充:8 字节的倍数就由我来组成!
有无压缩指针的区别
把 64 位 JVM 的指针压缩为 32 位,即引入压缩指针的原因是为了节省内存,但其实 64 位 JVM 的指针本来就可以是 64 位。
从 8 字节压缩到 4 字节,听起来好像才少了 4 个字节,但要知道,因为 Java 对象要补齐 8 字节的倍数;假如一个 Java 对象刚好满足了 8 字节整数倍,但因为没有压缩指针多出来 4 字节,这时又因为要补齐,还需要再补上 4 字节,一个对象就多了 8 字节!听起来好像还不怎么多,但这可是一个对象就少 8 字节,如果是一个大项目,差的可能就不是一星半点了。
所以肯定是开比不开好(JDK1.6 的版本后,64 位的 JVM 默认情况下是开启指针压缩的。)
冰激凌 🍦
我的心也终于放下了,马上下楼买冰激凌吃~
写在最后
我是苏易困,大家也可以叫我易困,一名 Java 开发界的小学生,文章可能不是很优质,但一定会很用心。
之前一直有自己写博客的想法,但无奈真的太拖延了,说懒说躺平都行,而且我也不是说真就很忙,忙到连码字的时间都没有了,都是自己给自己找的借口。
但自己其实也在不停地学习,奈何一直没有系统性地整理过,作为萌新,我真心觉得写博客跟其他大佬们交流真的是一件好事,很多东西其实你自己刚开始也不懂,但你为了整理成文章就需要去了解和学习更多,而且如果你能把这些知识传授给别人,别人也能听懂,那我觉得这些知识才是真的跟你自己融会贯通了。
确实真的不能再这样下去了,一定要克服自己的惰性,精力管理真的很重要,健身也要重新捡起来。
大家如果有什么建议或者文章有什么问题也都可以提出来,一起共同加油~







