
Redis数据结构详解(1)-redis中的字符串(SDS)
前提知识 🧀
我们先从百科上摘下 Redis 的解释:
Redis是一个使用 ANSI C 编写的开源、支持网络、基于内存、分布式、可选持久性的键值对存储数据库。
(不用过多在意 ANSI,它只是一个标准,你可以理解为早期民间版本很多,后来统一了标准,大学课程里包括现在在用的都是标准化后的 C 语言版本)
没错!Redis 的底层是由 C 语言 实现的!大学不管是什么专业应该都有这个课,但是不管大家还有没有它的记忆,都不影响我们接下来的学习哈哈哈~
redis 第一步,字符串是基础
回想当初学习 Java,第一个学习的数据类型应该是基本类型,但 redis 里最基础的结构其实是字符串,几乎哪里都有它。在 mysql 定义字段类型时,个别老哥会很中意 varchar 这个类型,因为万物皆可 varchar(不讨论性能的情况下),其实 redis 就有点这个意思,很多结构的基础都是字符串。
上面提到 Redis 的底层是由 C 语言实现的,那岂不是直接拿 C 语言的字符串(以空字符结尾的字符数组,以下简称 C 字符串)来用就行?
我先回答了:不行,因为 C 语言作为早期的编程语言,C 字符串是有些“不足”或者说是需要补充的,尤其是像 redis 这样对速度要求严苛,字符串可能会被频繁修改的服务,于是 redis 在 C 字符串的基础上,自己构造了名为 简单动态字符串(simple dynamic string,SDS)的抽象类型,用作 redis 自己的默认字符串。
(redis 也不是就不用 C 字符串了,只会运用在一些无需对字符串值做修改的地方,例如打印日志时)
C 字符串简单介绍,嗯,简单。
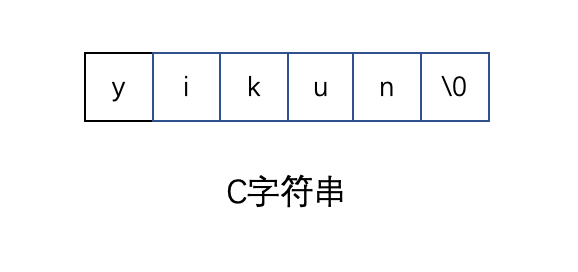
首先上图就是一个值为”yikun”的 C 字符串。
不了解的小伙伴可能不知道为什么后面多了个’\0’,其实这个字符是空字符,也可以理解为 C 语言的“字符串终止符”。
长度为 N 的字符串,会用长度为 N+1 的字符数组来表示,最后多出来的 1 长度就是专门用来存储空符’\0’的。
然后没了。
C 语言的字符串就是这么简单。
不急,我们继续往后说~
那么 C 字符串有哪些“不足”呢?
俗话说得好:知己知彼,百战百胜。
我们得知道 C 语言的“不足”,才能知道 redis 为了弥补这种情况,在 SDS 中做了什么措施。
1.C 字符串并没有记录自身长度。 2.会根据空字符’\0’来判断字符串是否结束。 3.只能根据空字符’\0’来判断字符串是否结束。
2 和 3 好像差不多,但意思其实是有细微差别的。
(果然中华文化博大精深~)
C 字符串因为上面的“不足”会引起什么问题?
1.获取字符串长度复杂度高
因为 不足 1 和 不足 3,所以 C 字符串只能通过遍历字符来获取长度。
我们这里用 Java 的 for 循环(只是用 Java 举例,实际是 C 语言实现的)简单说明下 C 语言如何获取字符串长度。
可见字符串越长,这个操作就越耗时,复杂度为 O(N)。
2.缓冲区溢出 和 内存泄露
因为 不足 2,C 字符串可能会在修改字符串时出现问题,因为大家知道内存是连续的,假如我要在字符串后面拼接新的内容,我首先要通过 内存重分配 来扩展底层数组的空间大小。
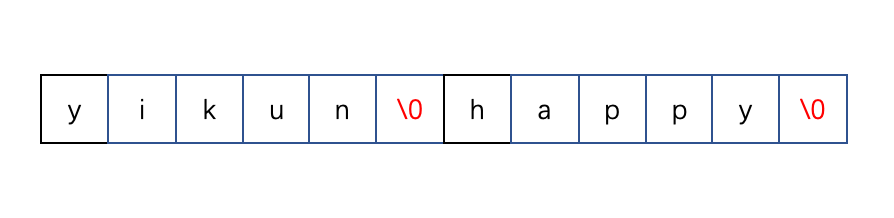
比如我要在字符串’yikun’后拼接’lucky’,但现在后面紧挨存储的是’happy’字符串,所以我首先要扩展数组才能拼接’lucky’,不然就把’happy’给覆盖掉,造成缓存区溢出了。
那如果我要缩短’yikun’,改成’yi’,倒是不用扩展数组。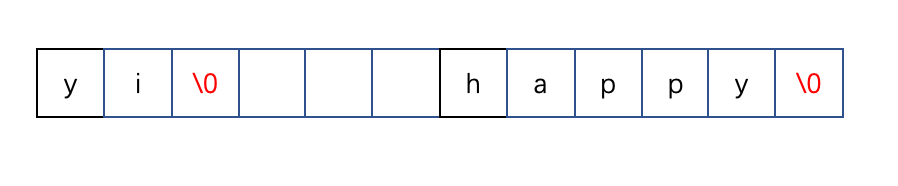
但我空的这部分又造成内存泄漏,所以还是需要进行 内存重分配。
而 内存重分配 是个十分耗时的操作,如果上面的字符串修改频繁发生的话,对于性能的影响就会很大。
3.没办法存储二进制数据
因为 不足 3,假如我们的数据本身就包含空字符串’\0’,而代码逻辑是铁面无私的,会认为是字符串终止的意思;而像图片、音频、视频、压缩文件这样的二进制数据是会包含空字符串’\0’的,所以可想而知,数据会出现问题,可能只能识别到前面的部分数据,而丢失后面的内容。
所以针对上面的问题,redis 的 SDS 的结构是怎么设计的?
废话不多说,我们直接来看下 SDS 的结构: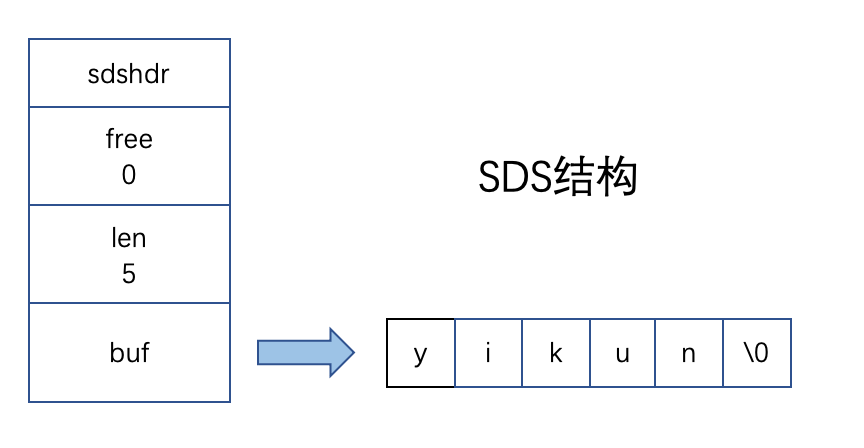
直观来看,SDS 多维护了 free 属性和 len 属性。
len 属性用来记录 buf 数组中已使用字节的数量,同时也等于 SDS 所保存字符串的长度。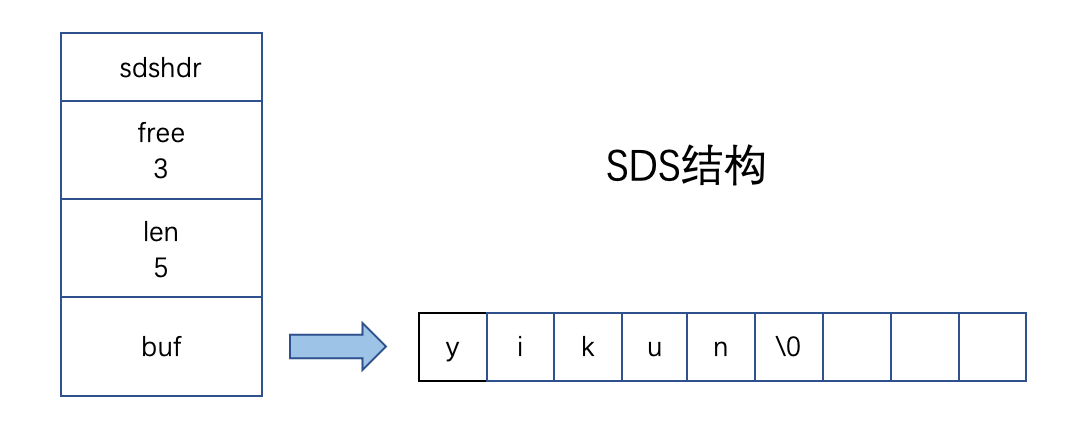
而属性 free 是用来记录 buf 数组中未使用字节的数量。
SDS 是如何依靠引入两个属性值 len、free 来解决具体问题呢?
1.获取字符串长度
现在可以直接访问 len 属性来获取字符串长度,就好比 Java 属性的 get 方法,复杂度由原来的 O(N)一下子降到了 O(1)。
而且这个属性是 SDS 在执行操作时自动完成的,我们无需进行任何维护。
2.空间预分配 和 惰性空间释放
上面我们说内存重分配操作耗时,所以在需要对 SDS 进行空间扩展的时候,会分配额外的未使用空间。
下面是额外分配空间数量的公式: 1.如果 SDS 修改之后,SDS 的长度(len 属性的值)小于 1MB,那么就会分配和 len 属性同样大的未使用空间,也就是 free 属性会和 len 属性相同,相当于将原数组长度 double。 2.如果 SDS 修改之后,SDS 的长度(len 属性的值)大于或等于 1MB,那么就会分配固定的 1MB 未使用空间。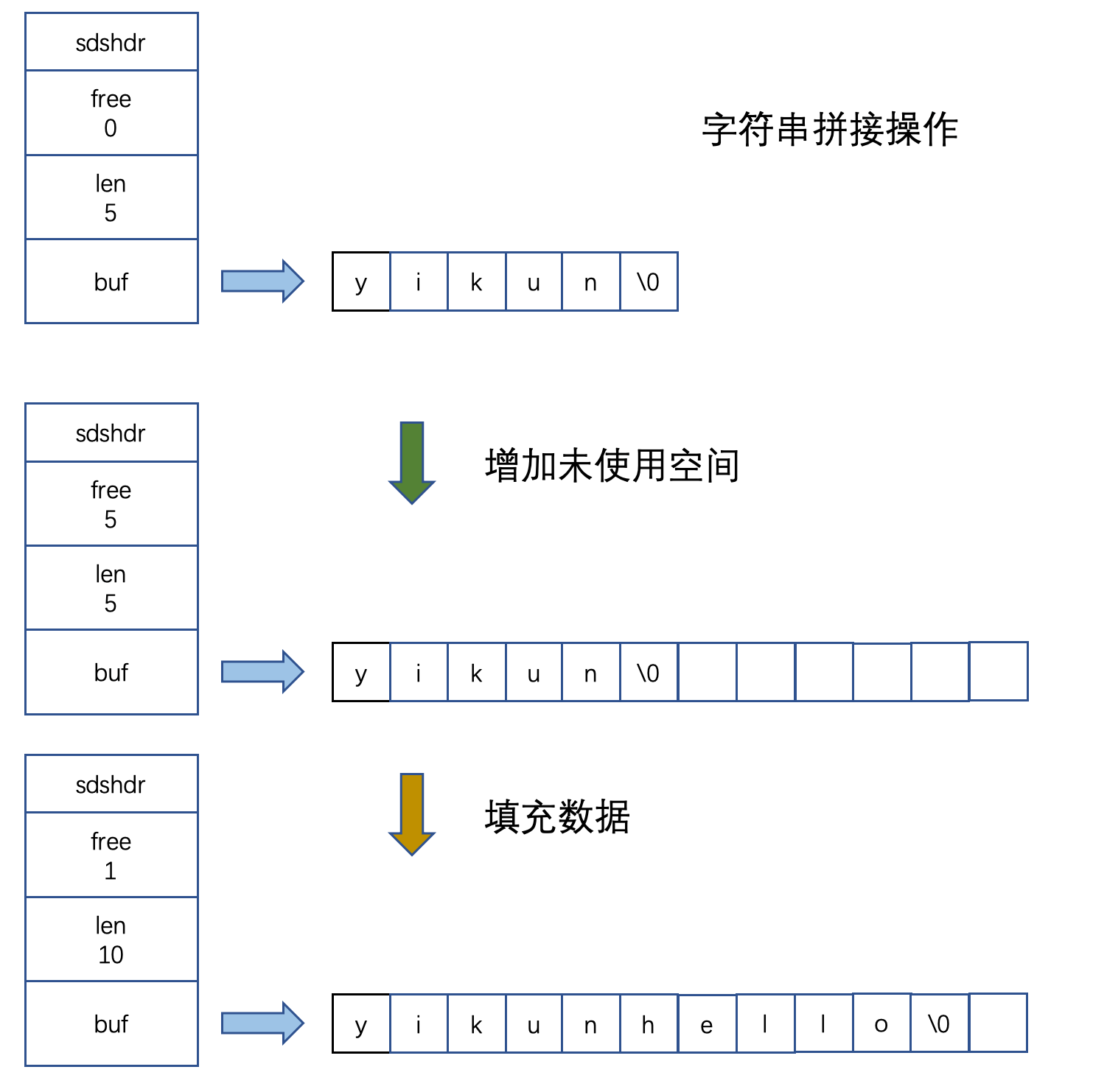
而 free 属性就决定了是不是需要进行额外的内存重分配操作,假如 free 为 7,而你需要拼接的字符串长度只有 5,那就不需要进行内存重分配操作,直接存储就可以。
free:太好了,我这空座就是给老弟你留的,快坐快坐~
所以针对拼接操作来说,本来 N 次 一定需要 N 次的内存重分配操作,现在 最多只需要 N 次。
(比如你第一次拼接后,free 就大于后续要拼接的字符串长度之和了,那其实就只有 1 次内存重分配操作,所以说最多 N 次)
缩短操作也是同理,删掉 N 个字符后,我 free 就增加 N,我先不做内存重分配操作,就先给你留着呗,万一你后面又做拼接是不是。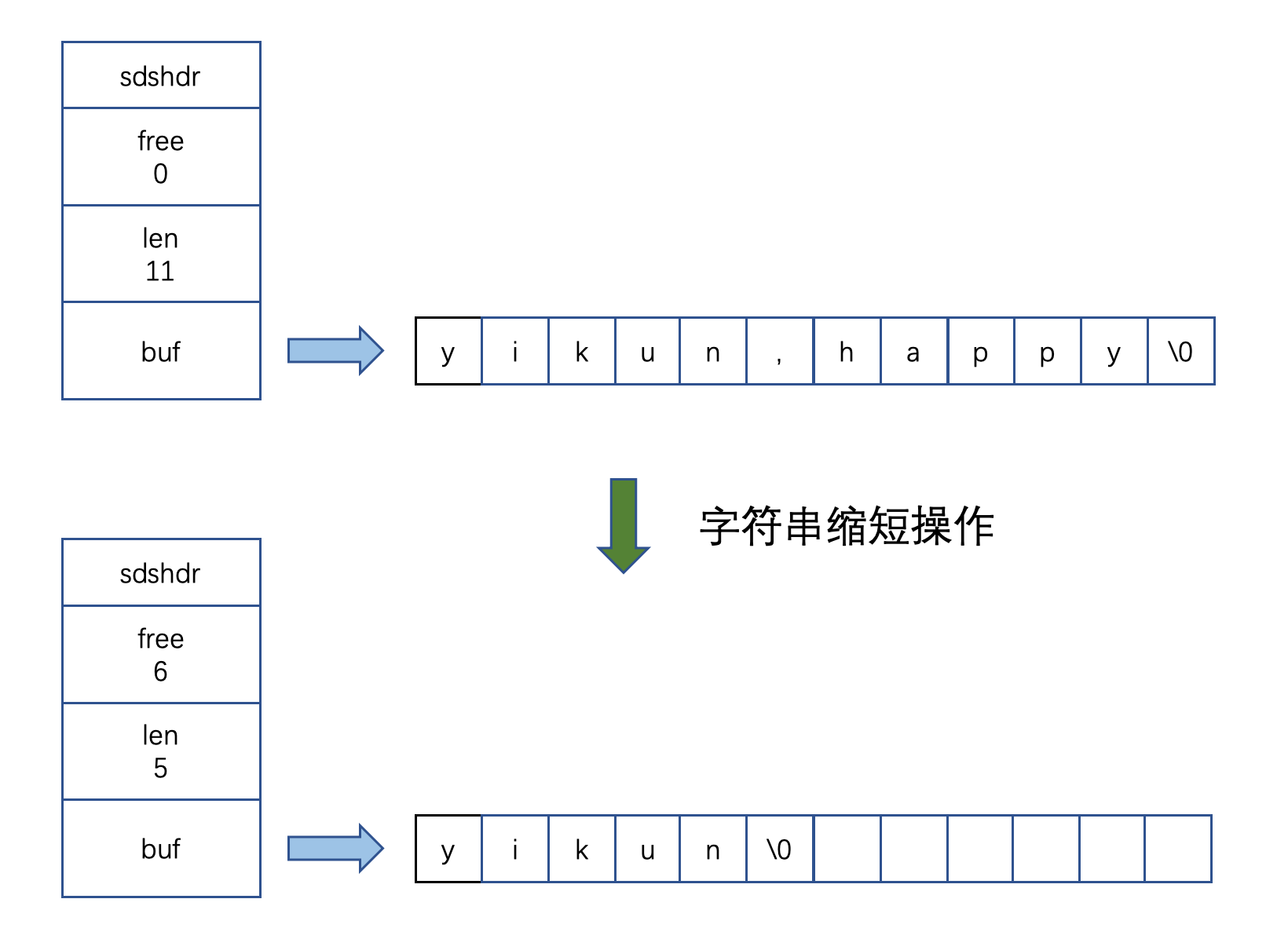
所以总结:拼接时我们做 空间预分配,缩短时我们做 惰性空间释放,都是为了 减少内存重分配操作。
(SDS 其实也提供了响应的方法,在有需要时,可以真正地释放 SDS 的未使用空间,所以不用担心未使用空间会造成内存浪费。)
3.存储二进制数据
C 字符串不能存储二进制数据的原因是只能根据’\0’来判断数据是否结束,不能保证其完整性,但因为 SDS 的 len属性,无论你数据里有多少’\0’都没关系,我是根据 len属性值来判断数据长度的,必定是完整的,所以 SDS 可以安全地存储二进制数据。
SDS 你都有 len 了,那为啥还要跟 C 字符串一样在字符串后面加’\0’?
这个很好回答,因为 SDS 保持和 C 字符串一样的特性,就不用专门编写多余的函数了,在一定的情况下可以直接用 C 语言的函数,避免了不必要的重写。
最后的总结
C 字符串和 SDS 之间的区别:
| C 字符串 | SDS |
|---|---|
| 获取字符串长度复杂度为 O(N) | 获取字符串长度复杂度为 O(1) |
| 修改字符串时需要执行 N 次内存重分配 | 修改字符串时最多需要执行 N 次内存重分配 |
| 不能保存二进制数据 | 可以保存二进制数据 |
| 可以使用 C 字符串函数库的所有函数 | 可以使用 C 字符串函数库的一部分函数 |
写在最后的最后
我是苏易困,大家也可以叫我易困,一名 Java 开发界的小学生,文章可能不是很优质,但一定会很用心。
呜呜呜~ 真是边整理便有收获,自己学习的动力也增长了起来,还真是那句话:你自己明白,才能跟其他人说明白(也不知道是不是说明白了),而且写的时候也会考虑一些取舍,比如有的东西需不需要标注?有的地方是不是过于啰嗦了?是不是写的太入门了一点?可能这些知识在一些人看来都是很基础很入门甚至不用讲的东西。
但怎么说呢,我的初心其实也就是整理和梳理自己的知识,如果能帮到你,我会很开心;如果你觉得不够水平,我也会虚心接受;人嘛,总要有个学习的过程,我也会一直努力的~ 大家一起加油~







